Ruteo de la Información.
Ruteo estático. Ruta default. Protocolos de ruteo dinámico.Protocolo no
orientado a la conexión. Protocolo no fiable. Tipo de servicios. Time tolive.
Fragmentación. Cheksum. Protocolo de control de trasmisión TCP/UDP.
Transferencia básica. Fiabilidad. Control de flujo. Multiplexación. Conexiones.
Sincronización de N4. Protocolo UDP. Formato. Diferencia con TCP. Aplicaciones
en TFTP.
Unidad II
Protocolo
FrameRelay. Líneas digitales. Formato de trama de nivel 2. Concepto de
congestión. BECN. FECN. DE. CIR. Concepto de circuito virtual permanente. PVC.
Redes MPLS Multi-ProtocolLabelSwitching. Redes de servicios convergentes de
voz, datos y video. Redes full malla. Calidad de servicio (QoS). Análisis del
datagrama IP de capa 3 para priorización de tráfico. Clases de servicio. Real
time, Assuredforwarding y Besteffort. Parámetros de performance. Paquetes
perdidos. Delay y Jitter. Normas G.711 y G.729 (compresión de voz). Cálculo de
ancho de banda de Voz sobre IP en LAN y WAN para diferentes tiempos de muestro.
Unidad III
Retardo de serialización. Paquetes por segundo. RTP (Real
Time Protocol). Tecnologías XDSL. ADSL Asymetric Digital Suscriber Line, SDSL
Symetric Digital Suscriber Line, Bucle de abonado, Distancias. Modulación,
Espectro en frecuencia. Módem ATU-R. (Terminal remota). Módem ATU-C (Terminal
de central). Multiplexor DSLAM. Spliter pasa alto y pasa bajo. Multiplexor por
División de Frecuencia. Concepto de subportadoras de bajada y subida.
Principios básicos de ATM.
Ruteo de la Información
2) Qué es el ruteo? Quiénes realizan esta operación?
3) Cómo puede configurarse el ruteo? Cuáles son las rutas estáticas?
4) Explica el ruteo estático. Cuáles son sus desventajas?
5) Qué permiten los protocolos de ruteo?
6) Cuáles son los beneficios del ruteo dinámico?
7) Explica los Protocolos IGP (Interior Gateway Protocol), y Protocolos EGP (Exterior Gateway Protocol)
El ruteo, en su forma mas básica, es el proceso de mover datos entre redes en capa 3. Si bien los routers son los dispositivos que comúnmente realizan esta operación, muchos dispositivos de seguridad y switches también implementan funciones de ruteo.
El ruteo en una red puede configurarse de forma estática, dinámica, o una combinación de ambos. Las rutas estáticas son utilizadas en ambientes de networking para múltiples propósitos, incluyendo una ruta default hacia alguna red con una única conexión. El ruteo estático es ideal en redes pequeñas donde se cuenta con pocos routers y redes, requiriendo un control absoluto del ruteo (se configura en cada equipo). De todas formas, el ruteo estático presenta muchas desventajas que lo hacen inapropiado para redes medianas y grandes, donde el crecimiento y el cambio es constante. En este tipo de redes, la mejor opción es implementar un protocolo de ruteo dinámico.
Los protocolos de ruteo permiten que los dispositivos de capa 3 aprendan y compartan de forma dinámica la información de ruteo. De esta forma, los equipos que habiliten dicho protocolo, intercambiaran toda la información de prefijos, parámetros y atributos de rutas entre sí. Cuando un dispositivo agrega, cambia o remueve alguna información en particular, el cambio se propaga y el resto de los equipos se actualiza de forma dinámica.
Como beneficios del ruteo dinámico se pueden nombrar:
Reducción drástica de tareas administrativas: Los equipos aprenden la información automáticamente, y no es necesaria la configuración manual de las rutas en cada equipo.
Disponibilidad: Durante situaciones de fallas, los protocolos de ruteo generan un nuevo camino alrededor de la falla automáticamente, sin necesidad de cambiar la configuración.
Escalabilidad: Los dispositivos manejan fácilmente el crecimiento de la red, calculando caminos de forma automática.
Los protocolos de ruteo, según su ámbito de aplicación se dividen en Protocolos IGP (Interior Gateway Protocol), y Protocolos EGP (Exterior Gateway Protocol)
IGP
Los protocolos de ruteo de tipo IGP se utilizan dentro de un sistema autónomo (AS). Los IGP son responsables de construir y mantener la información de ruteo dentro del dominio administrativo (AS) y por este motivo se los considera "internos". Estos protocolos forman la estructura del AS, y considerando su aplicación en redes extensas, como ISPs, las características primordiales con las que deben contar son robustez, rápida convergencia y optimización del tráfico generado por los mismos. Es de vital importancia que la red interna del proveedor ISP sea eficiente, robusta y segura; y es por esto que los protocolos IGP se diseñan para cumplir con estos parámetros. En una implementación correcta, el IGP no debería tener que mantener muchos prefijos (esto afecta su performance), y no debería contar con prefijos externos al AS, salvo algunas excepciones.
Los protocolos IGP pueden ser divididos en dos categorías: protocolos de tipo "distance-vector" y protocolos de tipo "link-state". Los protocolos de tipo distance-vector tienen en cuenta la cantidad de saltos al tomar la decisión del camino que debe atravesar un datagrama para llegar a destino, sin tener en cuenta las características del salto. Los protocolos de tipo "link-state" tienen en cuenta parámetros de los links, como ancho de banda de los links que se atraviesan, para tomar la decisión. Los protocolos IGP que han sido estandarizados y se utilizan hoy en día son: RIP (distance-vector), OSPF (link-state) e IS-IS (link-state); siendo los dos últimos los más populares y eficientes.
EGP (BGP)
Un protocolo de tipo EGP se utiliza para intercambiar información de ruteo entre diferentes AS. El único protocolo utilizado hoy en día como EGP es BGP (Border Gateway Protocol). Todos los esfuerzos de desarrollo de diferentes ingenieros, grupos y empresas se centran en mejorar y ampliar las prestaciones de este protocolo, y no en desarrollar nuevos estándares. Esto se debe a que BGP es el protocolo de Internet, utilizado por todas las organizaciones que deseen interconectarse. Por ser utilizado entre diferentes dominios administrativos, y por transportar mucha información (todos los prefijos de Internet) debe ser un protocolo granular a nivel de políticas de interconexión, aplicando mecanismos para asegurar el transporte de información. Estas son las premisas con las que se diseñó BGP.
BGP es un protocolo de tipo “path-vector”. Utiliza los números de AS como vector, para evitar “loops” en el enrutamiento. Este protocolo forma un vector que contiene todos los números de AS que ha atravesado dicho anuncio, y por ende indica el camino que toma el paquete en la red (Saltos de AS). BGP intercambia rutas entre diferentes AS, y esto hace que BGP utilice a los AS como sus "saltos", indicando los trayectos a nivel de sistemas autónomos y no routers. BGP utiliza la información que recibe para armar una base de datos que contiene toda la información de alcance de la red, que a su vez intercambia con otros vecinos BGP.
BGP se ha extendido para poder transportar otros tipos de familias de direccionamiento. De esta forma, puede transportar rutas IPv6, VPN-IPv4, VPN-IPv6 y etiquetas MPLS, entre otras. Cuando se configura al protocolo BGP para transportar otra familia de direccionamiento, al mismo se lo llama "Multi-Protocol BGP (MP-BGP)".
Para responder las preguntas que a continuación adjunto, deben leer el material. 3) Qué es una estructura de datos?
4) Por qué son útiles?
5) Qué es un array? Elementos de un array. Clasificación de arrays.
6) Compara tus respuestas a los conceptos vistos en los videos.
7) Realiza un análisis de de todos los videos vistos. Realiza una red conceptual sobre Estructuras de datos.
Todos los trabajos deben estar en sus carpetas
Estructuras de Datos
Lo primero que debemos tener claro es la definición de “estructura de datos” y que a partir de esta definición parten otros conceptos y tipos. Que las estructuras de datos se estudian como conceptos sobre programación, y no sobre un lenguaje de programación en específico, por lo que cada lenguaje puede tener diferentes implementaciones de estructuras de datos. En este post no cubriré el tema de complejidad algorítmica de las estructuras, pero si mencionaré conceptos que hacen referencia a dicha complejidad, sin llegar a fondo.
Una “estructura de datos” es una colección de valores, la relación que existe entre estos valores y las operaciones que podemos hacer sobre ellos; en pocas palabras se refiere a cómo los datos están organizados y cómo se pueden administrar. Una estructura de datos describe el formato en que los valores van a ser almacenados, cómo van a ser accedidos y modificados, pudiendo así existir una gran cantidad de estructuras de datos.
Lo que hace específica a una estructura de datos es el tipo de problema que resuelve. Algunas veces necesitaremos una estructura muy simple que sólo permita almacenar 10 números enteros consecutivamente sin importar que se repitan y que podamos acceder a estos números por medio de un índice, porque nuestro problema a resolver está basado en 10 números enteros solamente. O tal vez nos interese almacenar N cantidad de números enteros y que se puedan ordenar al momento de insertar uno nuevo, por lo que necesitaremos una estructura más flexible.
¿Por qué son útiles las estructuras de datos?
Las estructuras de datos son útiles porque siempre manipularemos datos, y si los datos están organizados, esta tarea será mucho más fácil.
Considera el siguiente problema:
¿De qué forma puedo saber si una palabra tiene exactamente las mismas letras que otra palabra? O dicho de otra forma, ¿cómo saber si una palabra es una permutación de otra palabra?.
Si queremos resolver este problema con papel y lápiz, basta con escribir las palabras y visualmente identificar si ambas palabras tienen las mismas letras, una forma rápida es contar mentalmente el número de cada tipo de letra en ambas palabras y si tienen el mismo número entonces si es una permutación.
Como resolver el problema de permutación de palabras en papel
Pero si quisiéramos resolverlo mediante programación tenemos que decirle a la computadora como saber que es una palabra y decirle cómo debe comparar las palabras de la misma forma en que lo resolvimos en papel y lápiz, ¿Se te ocurre alguna forma?.
Qué tal si pensamos en las palabras como una estructura de casillas de letras secuenciales (array ó arreglo) donde cada letra representa una casilla en esta estructura. A cada casilla le damos un índice con el cual podemos acceder a ella para saber qué letra tiene contenida, esto le indicará a la computadora cómo reconocer una palabra.
Estructura de datos array
Ahora, para resolver el problema debemos saber cómo comparar las palabras y sus letras, lo primero que podemos evaluar es el length ó longitud de la palabra, o sea, cuántos caracteres tiene; si las palabras tienen diferente número de caracteres entonces no tiene sentido comparar más, ya sabemos que NO tendrán exactamente las mismas letras. Lo siguiente será contar las letras por tipo de letra. En el ejemplo anterior de las palabras “casa” y “saca” contamos las letras mentalmente, pero las escribimos en el papel con una estructura muy específica, cada letra que encontramos se asocia al número que contamos; entonces, ¿habrá alguna estructura de datos que me ayude a asociar las letras con el número que contamos?, la respuesta es sí. Podemos pensar en esta asociación como una estructura de tipo key-value (llave-valor) llamada dictionary ó diccionario, donde la letra es la llave y su valor asociado es el número contado; además, en esta estructura no debemos repetir la llave porque de lo contrario tendremos letras repetidas y no podremos contar, es por eso que la estructura dictionary es distinta al array, ya que en el array si podemos repetir letras, pero en esta otra estructura no deberíamos permitirlo ya que eso sería lo que nos permita resolver el problema de contar.
Estructura de datos map
De modo que para operar la estructura array tenemos que hacerlo recorriendo una a una todas las casillas para obtener las letras mediante su índice; la casilla 0 contiene a la letra “c”, la casilla 1 contiene la letra “a” y así sucesivamente. Para el caso de la estructura dictionary podemos decir que vamos a operar en ella a través de su key (llave); la llave “c” tiene asociado el valor 1, la llave “a” tiene asociado el valor 2, y así sucesivamente. Cada vez que encontremos una letra la pondremos en la estructura dictionary, si no existe se agrega y se asocia con el valor 1, sí ya existe entonces “contamos” y a su valor le sumamos +1.
Hasta este punto las estructuras de datos nos han ayudado a resolver este problema con el simple hecho de tener nuestros valores organizados y definiendo la forma en la que podemos operar sobre ellos; aún quedan varios pasos más para resolver el problema por completo pero eso pasa a ser objeto de otro tema en programación que son los algoritmos. Por ahora nos basta con identificar las estructuras de datos.
Tipos de estructuras de datos
Al hablar de estructuras de datos debemos pensar en primera instancia en cómo los datos se representan en la memoria, ¿se trata de estructuras contiguas o enlazadas?, al partir de esta pregunta podemos darnos la idea correcta sobre la base de nuestra estructura y cómo es que los datos se van a almacenar.
Las estructuras contiguamente asignadas están compuestas de bloques de memoria únicos, e incluyen a los arrays, matrices, heaps, y hash tables.
Las estructuras enlazadas están compuestas de distintos fragmentos de memoria unidos por pointers ó punteros, e incluyen a los lists, trees, y graphs.
Los contenedores son estructuras que permiten almacenar y recuperar datos en un orden determinado sin importar su contenido, en esta se incluyen los stacks y queues.
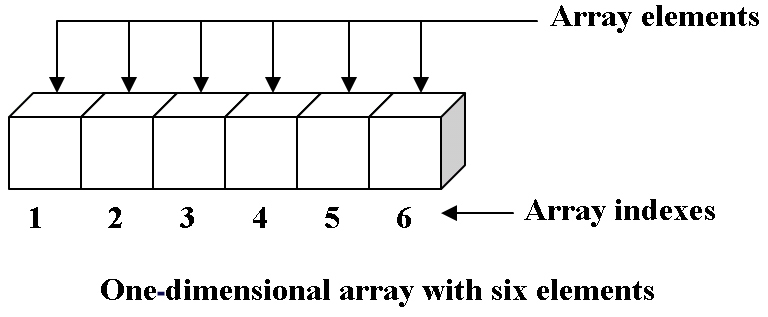
Array
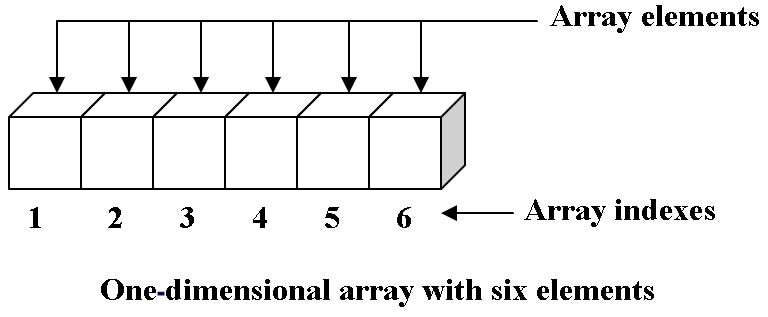
Esta estructura es “la” fundamental de las estructuras contiguamente asignadas. Arrays ó arreglos son estructuras de datos de tamaño fijo de modo que cada elemento puede ser eficientemente ubicado por su index (índice) ó dirección. Exactamente como lo vimos en el ejemplo anterior un array tiene una tamaño fijo y una dirección (index) con la cual podemos localizar de forma rápida un elemento en el arreglo, de modo que podemos apuntar a un elemento en el array de la siguiente forma: array[index], donde array es el nombre de nuestra estructura, seguida de dos “corchetes” que abren y cierran, donde especificamos el index que deseamos apuntar.
Los arrays muestran algunas ventajas con respecto a otras estructuras, como por ejemplo:
Al tener un espacio contiguo en memoria cada index de cada elemento del array apunta directamente a una dirección de memoria, de esta forma podemos acceder arbitrariamente a los datos de forma instantánea puesto que sabemos la dirección de memoria exacta. Esto deriva en un acceso de tiempo constante dado por los index.
Los arrays son puramente datos lo que significa que no es necesario desperdiciar espacio en memoria almacenando información extra que ayude a la localización de sus elementos como es el caso de las estructuras enlazadas, los arrays tienen eficiencia de espacio.
Localidad de memoria, es común que en la programación los datos de una estructura sean iterados (o recorridos) y los arrays son buenos para esto ya que exhiben excelente localización de memoria, permitiéndonos aprovechar la alta velocidad de la caché en computadoras modernas.
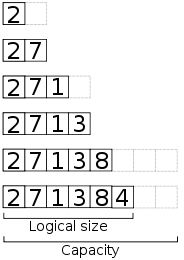
La gran desventaja de los arrays es que no podemos ajustar su tamaño a la mitad de la ejecución de un programa, pero ¿y qué tal si creamos uno nuevo con la nueva dimensión deseada?; esto sería bueno si supiéramos el tamaño que deseamos todo el tiempo, pero si no lo sabemos sólo tenemos 2 opciones: crear una array lo suficientemente grande para almacenar nuestros datos, pero esto deriva en un desperdicio de memoria totalmente innecesario, ó podemos crear un nuevo array, doblar el tamaño de éste cada vez que se necesite crecer y copiar los datos del array anterior al nuevo array, hacer esto tiene el mismo nivel de complejidad que si tuviéramos un array único suficientemente grande, pero con la ventaja de que sólo va a crecer cuándo sea necesario, evitando así desperdiciar memoria. Es pues que de esta forma podemos alargar un array en tiempo de ejecución, a este concepto se le conoce como dynamic arrays ó arreglos dinámicos.
Los arrays son la base de muchos otros tipos de estructuras de datos como acabamos de ver con los arreglos dinámicos.
Otra estructura muy común que nos ayuda a representar datos reales son las llamadas matrices o tablas que no son mas que arrays de múltiples dimensiones. Pensemos, si un arreglo es una colección consecutiva de valores, se puede decir que son de tipo lineal en una dimensión plana ó uni-dimensionales, si quisiéramos formar una matriz o tabla (matrix o table) podríamos crear un array bi-dimensional, lo que quiere decir que tendremos que localizar a un elemento por su index [i , j], o bien su ubicación lineal a la derecha y hacia abajo como en un plano cartesiano con dimensiones xy asemejando a una tabla, o podríamos crear un array tri-dimensional, agregando una dimensión más de “fondo”, que haría que localizáramos a un elemento en su index [i, j, k], en plano cartesiano como xyz. Además existe una tercer clasificación conocida como jagged arrays o matrices dentadas como se ve en la siguiente imagen, donde vemos un arreglo de tipo bi-dimensional pero con la diferencia de que una de sus dimensiones no es rectangular sino que puede tener distintos tamaños formando así una matriz dentada.
Clasificación de arrays en múltiples dimensiones
Puedo decir que este es un resumen sobre los arrays, uno que sin duda nos ayudará a identificar de forma más rápida el tipo de “array” que necesitamos usar.
Estructuras enlazadas (linked structures)
La magia de las estructuras enlazadas es dada por los pointers o punteros, que como su nombre lo indica apuntan a una dirección de memoria donde se encuentra ubicado un valor. Los pointers son los encargados de mantener los “enlaces” entre valores de modo que es posible tener una secuencia de valores todos enlazados por pointers. Si ponemos atención a la definición de los pointers podemos deducir que los valores no necesariamente tienen que estar localizados en memoria uno después del otro como en le caso de los arrays que son contiguamente asignados, por lo que podemos tener los valores ubicados en distintas localidades de la memoria y aún así representar un colección de valores consecutivos.
Representación de una secuencia de valores enlazada por punteros
Como se observa en la imagen, tenemos una secuencia de valores enlazados por pointers llamados nodos, que están representados por un cuadro vacío y una flecha. El cuadro vacío representa el valor con la dirección de memoria a donde está apuntando el valor que contiene, de modo que: el valor 12 está enlazado por medio de un pointer que guarda la ubicación del siguiente valor en la secuencia que es el 19 y este a su vez guarda la ubicación al valor 37. Cuando hablemos de estructuras enlazadas debemos siempre pensar en que además de almacenar el valor que deseamos, debemos tener un espacio extra donde debemos almacenar la dirección de memoria del siguiente valor.
Después de una breve introducción a los pointers podemos pasar a la estructura mas común de las estructuras enlazadas que son las linked lists o listas enlazadas.
Linked lists
Comencemos por definir una “lista”. Una lista es aquella estructura que representa un número contable de valores ordenados donde un mismo valor puede repetirse y considerarse un valor distinto a otro ya existente. Las listas son consideradas secuencias de valores y cómo ya veíamos en la explicación anterior sobre pointers estos se pueden aplicar para implementar una lista de tal forma que las características principales de una lista serían:
Cada nodo en nuestra lista contiene uno o más campos que contienen el valor que deseamos almacenar.
Cada nodo contiene al menos un campo pointer apuntando a otro nodo, lo que significa que podemos tener 2 pointers, uno que apunta a un nodo consecuente y otro que apunta a un nodo previo formando así una lista doblemente enlazada (double linked list).
Es necesario tener un pointer que apunte a la cabeza de la estructura para así saber por dónde comenzar.
Representación de una liked list con sus respectivos punteros (imagen tomada del libro “The Algorithm Design Manual”)
¿Recuerdan cuando explicábamos el problema de la permutación de una palabra?, específicamente cuando hablábamos de representar una palabra en un array donde cada letra era una casilla, bien, aquí tenemos una lista de palabras lo cual puede claramente significar que es una lista de arrays. La mayoría de los lenguajes de programación representan a las “cadenas” (palabras, secuencia de caracteres, etc) como arrays de caracteres, es por eso que con otra estructura como las lists podemos tener secuencias de palabras pudiendo representar un párrafo de un libro o de un post de medium que habla sobre estructuras de datos :p
Ahora debo mencionar que las 3 operaciones básicas soportadas por una linked list son: búsqueda, inserción y eliminación de nodos. Suena obvio ¿no creen?, para explicar esto haré una comparación sobre ambos tipos de estructuras y quizá así quede más claro.
Array vs Linked list
Una diferencia grande entre los arrays vs linked lists es que insertar o eliminar de una linked list es más fácil ya que no tiene tamaño fijo y lo único que debemos hacer para insertar o eliminar un valor es simplemente apuntar al nuevo nodo creado, ó apuntar al siguiente nodo de la lista si un nodo fue eliminado. En un array no existe esta flexibilidad.
Si tenemos una gran cantidad de valores siempre será más fácil mover pointers de una valor a otro que mover los valores en sí.
En un array podemos provocar un desbordamiento de memoria (memory overflow) si queremos insertar un valor extra y ya hemos excedido el tamaño del array, lo cual no sucedería en una linked list.
Por otro lado en una linked list necesitamos más espacio en memoria para almacenar los pointers.
Los arrays tienen un mejor manejo del acceso aleatorio a los valores y son mucho mejores en la ubicación de los datos en memoria y aprovechamiento de la caché.
¿Cuál es mejor? Ninguna es mejor que la otra, todo dependerá de lo que necesitemos resolver. Imaginemos que estamos creando una estructura para almacenar los usuarios de nuestra aplicación, esta estructura debe guardar el username y su password, ya dijimos que las linked list son rápidas para insertar y eliminar, entonces ¿usaríamos una linked list?, si podríamos. Ahora si usáramos la linked list y quisiéramos obtener un username porque queremos saber su password para el log-in de nuestra aplicación ¿sería mejor usar un array?, el acceso en los arrays es más rápido ya que sabiendo la ubicación obtendremos el dato directamente, cosa que en la linked list no podríamos. Entonces, ¿cómo resolvemos este problema si queremos insertar y eliminar de forma eficiente, y también queremos acceder a los datos de forma eficiente?, podríamos combinar ambas estructuras, sí, hacer un array de linked list. De esta forma podríamos asignar a cada casilla del array una linked list por cada letra del abecedario, si deseamos agregar un username “Marcela” iríamos directamente a la casilla de la letra M e insertaríamos un nuevo nodo con el username y su password en la linked list. Y si queremos obtener el username podemos de nuevo ir a la casilla de la M y buscar en el linked list. De esta forma evitaríamos buscar en todos los usernames hasta encontrar el que queremos, y obtener y agregar nuevos datos se volvería mas fácil y rápido.
Contenedores
Las estructuras de tipo contenedor se caracterizan principalmente por la forma particular de recuperación ordenada de datos que soportan, y en los dos tipos principales de contenedores (stack y queue) el orden de recuperación depende del orden de inserción.
Stack
Un stack o pila, soporta la recuperación ordenada de datos last-in, first-out (LIFO) o bien: el último dato en entrar, el primer dato en salir. De la misma forma en que se hace en una pila de platos limpios, si necesitamos un plato limpio vamos a la pila y tomamos el primero de la pila, que en realidad fue el último plato que agregamos a ella. Las pilas son estructuras que encontramos de muchas formas en el mundo real, siempre que podamos apilar algún objeto como libros, cazuelas, películas o la forma en la que metemos latas de refresco en el refrigerador :)
Representación de un stack y sus operaciones push y pop
Tomando en cuenta lo anterior podemos pensar que si usamos un stack es porque probablemente el orden de la recuperación de datos no nos importa tanto, simplemente queremos apilarlos y des-apilarlos, por lo que las operaciones fundamentales en un stack son push y pop para poner y obtener datos de la pila.
Con push() insertamos un elemento en el tope de la pila, y con pop() retornamos y removemos el elemento en el tope de la pila, como se ve en la imagen.
Queue
Una queue o cola, soporta la recuperación ordenada de datos first-in, first-out (FIFO) o bien: el primer dato en entrar, es el primer dato en salir. Justo como una cola en el banco cuando vamos a realizar alguna operación con nuestra cuenta bancaria, si todos los asistentes están ocupados se genera una cola donde el primero que llegó será el primero en ser atendido y el resto esperamos en la cola. Este tipo de estructuras se utiliza mucho en el control de tiempos de espera de servicios, tiempos de ejecución en un CPU, de conexión de red, o en el mundo real en una cola para las tortillas, para entrar en una avenida rápida, etc.
Representación de una queue y sus operaciones enqueue y dequeue
En este tipo de estructura el orden sí importa, pues siempre el primero de la cola debe ser el primero en ser atendido y el resto de forma ordenada esperan su turno. Las operaciones de esta estructura son: enqueue y dequeue para encolar y des-encolar (poner y obtener de la cola).
De modo que enqueue() inserta un elemento al final de la cola, y dequeue() retorna y remueve el primer elemento de la cola.
Conclusión
Las estructuras de datos existen para ayudarnos en la compleja tarea de resolver problemas en programación, no importa el lenguaje de programación que utilices, si vas a manejar datos de cualquier tipo siempre caerás en el uso de estructuras de datos. Dicho esto, podemos concluir que tener una base sólida de entendimiento sobre las características de una estructura de datos nos llevarán a hacer la mejor elección para resolver nuestro problema, y de esta forma alejarnos de hacer una mala elección que nos pueda costar mucho: mucha memoria, mucho tiempo de ejecución, mucho tiempo de desarrollo.
En una segunda parte, escribiré sobre los diccionarios, hash tables, árboles y grafos.
1) Seguimos trabajando con el material que ocupamos en el salón de clases, antes de la cuarentena, por eso te propongo que veas el siguiente video: https://www.youtube.com/watch?v=gNdrxk5yTWU.
2) Toma nota sobre los conectores lógicos y las tablas de verdad. Recuerda el concepto de proposición.
3) Lee el material y mira el video sobre como se formalizan las proposiciones
Lógica proposicional
Estuadiaremos ahora con algo de detalle la Lógica proposicional, surgida a principios del siglo XX y que sentaría una de las bases de la construcción de ordenadores. Un mundo de unos y ceros.
Lo que vamos a estudiar a continuación son algunas nociones de la lógica tal como se concibe en la actualidad. Vimos que razonamos llevando a cabo inferencias; aquí se nos ofrece un instrumento para determinar la validez de las mismas, estudiaremos la lógica como un sistema formal que opera sobre los procesos de razonamiento mediante el cálculo, aplicando precisas reglas de inferencia. Seguramente los procedimientos de la lógica te recordarán bastante a las matemáticas. Esto no es casual, la lógica simbólica surge como resultado de la matematización de la lógica tradicional. Veamos cómo fue el proceso.
El lenguaje habitual empleado dentro de una comunidad que comparte el mismo idioma se denomina lenguaje natural. Es con éste con el que argumentamos y llevamos a cabo los desarrollos lógicos habituales. Sin embargo, a la hora de analizar un razonamiento partiendo de éste nos encontramos con serias dificultades; el lenguaje natural contiene numerosas lagunas y ambigüedades, esto impide la aplicación de un análisis lógico riguroso a partir del mismo. Necesitamos un lenguaje lógico que evite los inconvenientes del lenguaje natural.
Verdad de las proposiciones y validez de los razonamientos o inferencias
Sabemos que las proposiciones son o verdaderas o falsas a lo que añadimos ahora que las argumentaciones, razonamientos o inferencias serán correctas o válidas, pero no verdaderas o falsas. Debemos distinguir entre la verdad de las proposiciones y la validez o corrección de los argumentos. Veamos esto.
Formalización del lenguaje natural
Conocemos ya la notación simbólica empleada por la lógica proposicional. Nos encontramos ya en condiciones de convertir expresiones del lenguaje natural en otras formalizadas.
Podemos formalizar el lenguaje natural simbolizando su estructura lógica mediante los símbolos del lenguaje lógico.
Y ahora tú ... ¿te atreves?
Análisis lógico de los argumentos
Una vez formalizado un argumento es posible establecer, mediante tablas de verdad la validez de ese razonamiento; para ello deberemos descomponerla en sus elementos básicos e ir determinando los valores de verdad parciales hasta llegar al de la fórmula.
La deducción lógica
Siendo las tablas de verdad un instrumento adecuado para probar la validez de nuestros razonamientos, es cierto que se trata de un mecanismo que se vuelve muy laborioso cuando se aplica a un argumento extenso, especialmente si éste parte de más de dos variables proposicionales (recuerda que por cada una de ellas, las combinaciones de 1 y 0 se doblan; para p son dos, para p y q, cuatro, para p, q y r ocho, y así sucesivamente).




 Estructura de datos array
Estructura de datos array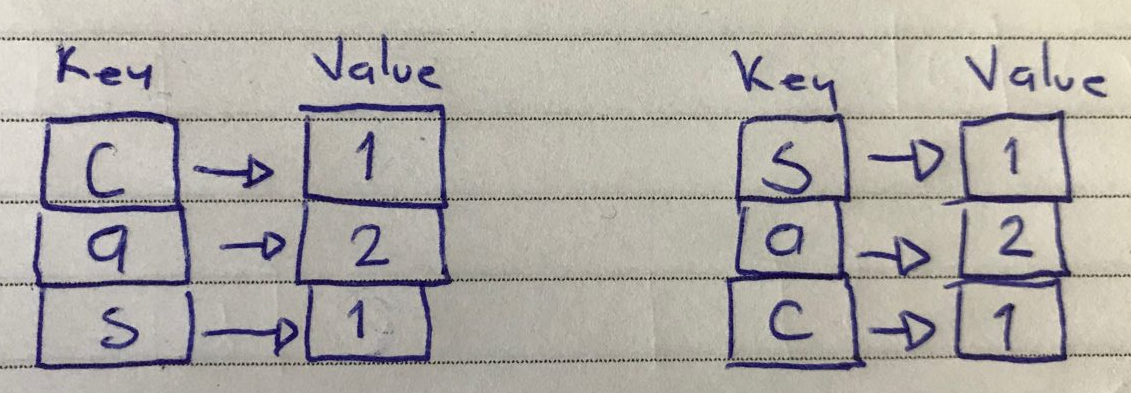 Estructura de datos map
Estructura de datos map
 Un
Un 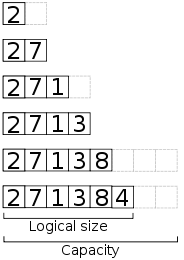 Ejemplo de como crecer un
Ejemplo de como crecer un 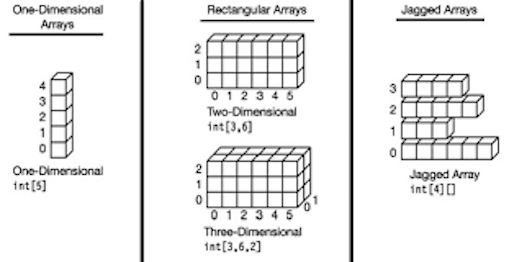 Clasificación de arrays en múltiples dimensiones
Clasificación de arrays en múltiples dimensiones Representación de una secuencia de valores enlazada por punteros
Representación de una secuencia de valores enlazada por punteros Representación de una liked list con sus respectivos punteros (imagen tomada del libro “The Algorithm Design Manual”)
Representación de una liked list con sus respectivos punteros (imagen tomada del libro “The Algorithm Design Manual”)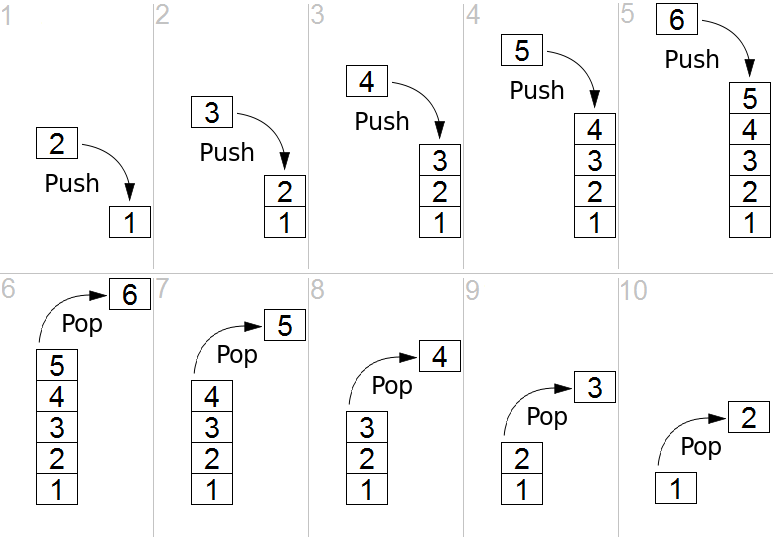 Representación de un
Representación de un 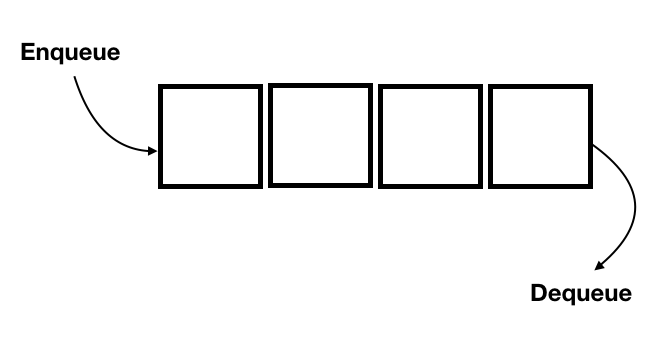 Representación de una queue y sus operaciones enqueue y dequeue
Representación de una queue y sus operaciones enqueue y dequeue


{kind=link}
{kind=link}
{kind=link}