Asignatura: Aplicaciones I
Curso: 4° Informática
Profesora: Evangelina Rivero
Tema: Planillas de Cálculo
Una planilla de cálculo es un software de aplicación utilizado para procesar datos por medio de operaciones simples o complejas.
Algunos ejemplos que utilizaremos en clase son:
- Ms Excel es una planilla de cálculo propietaria y pago.
- Open Calc es una planilla de cálculo libre.
- Gnumeric es una planilla de cálculo libre.
Estas tres no son las únicas, existen otras como pueden ser Social Calc, la planilla que ofrece Google Docs, KSpread de KOffice, Numbers, Lotus 1-2-3, Quattro pro, etc.
Una planilla está formada por hojas de cálculo en donde los datos se disponen en forma de tablas, la cual está dividida en columnas y filas. Los datos se ingresan en celdas que se definen como la intersección entre una columan y una fila.



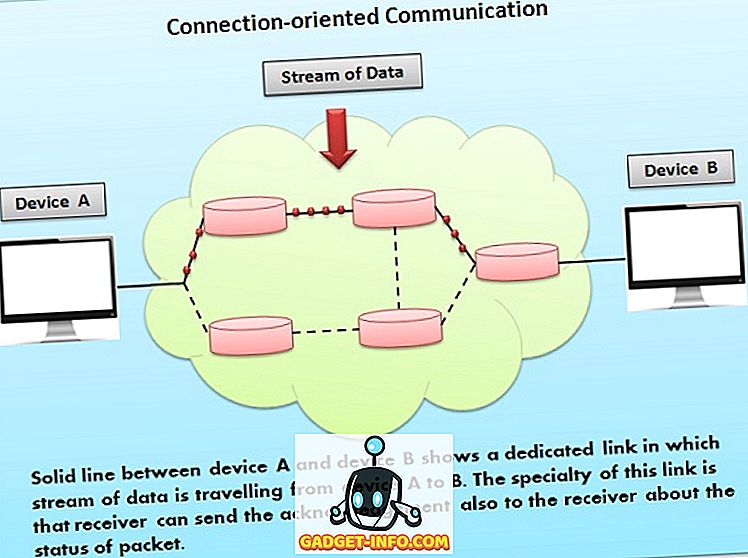
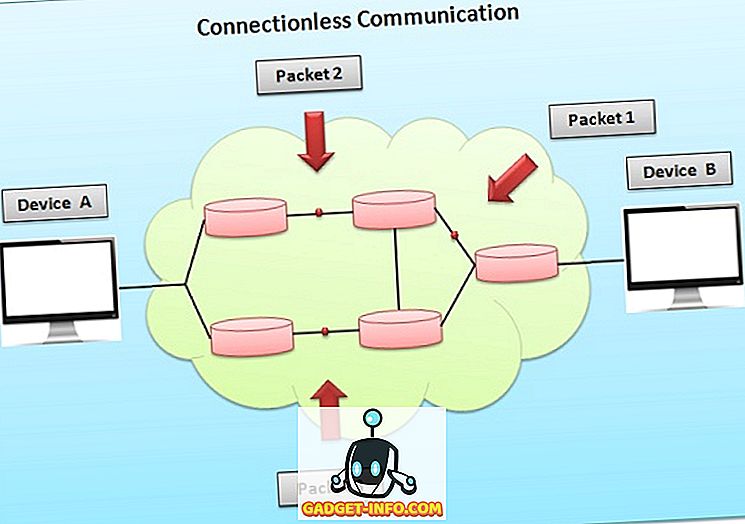
Si observamos las tres ventanas, podremos ver que no existen grandes diferencias entre estas tres planillas de cálculo. Clickea sobre las imágenes para agrandarlas y ver en detalle las características de las ventanas.
 Clickea sobre la imagen para ver en detalle las barras de menú y herramientas. Clickeando con el botón derecho sobre las imágenes podrás guardarlas utilizando la opción Guardar imagen como para que luego puedas imprimirla y pegarla en tu cuaderno.
Clickea sobre la imagen para ver en detalle las barras de menú y herramientas. Clickeando con el botón derecho sobre las imágenes podrás guardarlas utilizando la opción Guardar imagen como para que luego puedas imprimirla y pegarla en tu cuaderno.
CREACIÓN DE FORMULAS
Al introducir una fórmula hay que tener en cuenta lo dicho anteriormente, o sea, principalmente, las mismas deben comenzar con el símbolo de + o de =.
Las mismas pueden ser de tres tipos: fórmulas comunes, fórmulas en base a referencias, y una combinación de ambas.
Fórmulas comunes
Son las anotaciones de cualquier tipo de fórmula matemática, como por ejemplo:
+45*10/18
+23+11+15
+65-(11+56+98)
Fórmulas con referencias
Estas son las fórmulas que en vez de utilizar números, usan referencias de celdas para realizar los cálculos indicando al programa donde buscar los datos usando el contenido de la celda para los cálculos, por lo tanto al cambiar cualquiera de los datos de las referencias automáticamente se cambia el resultado de la fórmula, por ejemplo:
+A15*B3/H8
+C11+C12+C13
+D23-(E23+F23+G23)
Existen tres tipos de referencias: referencias relativas, referencias absolutas y referencias mixtas.
Referencias Relativas
La ventaja de usar referencias relativas en una fórmula es el hecho de que al copiar o mover la fórmula automáticamente se actualizan las referencias.
 El copiarla para F5 la misma se actualizará en todos sus argumentos una columna, ya que se copió en forma horizontal, por lo tanto quedará: +F1+F2+F3+F4.
El copiarla para F5 la misma se actualizará en todos sus argumentos una columna, ya que se copió en forma horizontal, por lo tanto quedará: +F1+F2+F3+F4.
Referencias absolutas y mixtas
Si bien usar referencias relativas representa una gran ventaja, ya que no se tendrá la necesidad de repetir varias veces una anotación de este tipo ya que podemos anotar una vez y después copiarla las veces que sea necesario, por otro lado puede generar un problema, analicemos el siguiente caso:
 La fórmula que calcula el IVA (+B2*B11) hace referencia a la celda B11 y está escrita para el primer registro, al copiarla para el segundo la misma se actualizará en filas ya que se copia verticalmente, por lo tanto quedará corrida un lugar en todas las referencias de filas (+B3*B12). En este caso la actualización de fórmula juega en contra de los intereses de la planilla ya que el primer argumento de la fórmula queda perfecto pero el segundo no, pues en la celda B12 no tenemos datos.
La fórmula que calcula el IVA (+B2*B11) hace referencia a la celda B11 y está escrita para el primer registro, al copiarla para el segundo la misma se actualizará en filas ya que se copia verticalmente, por lo tanto quedará corrida un lugar en todas las referencias de filas (+B3*B12). En este caso la actualización de fórmula juega en contra de los intereses de la planilla ya que el primer argumento de la fórmula queda perfecto pero el segundo no, pues en la celda B12 no tenemos datos.
Para solucionar estos problemas es que existen lo que llamamos referencias absolutas que es nada mas y nada menos que “fijar” el o los argumentos deseados para que estos no se actualicen al copiar o mover una fórmula. Esto se hace mediante dos símbolos de pesos ($), uno para la columna y el otro para la fila de la referencia, pudiendo usar de a uno (referencia mixta) o los dos (referencia absoluta), según de que forma se desee “fijar” esa referencia. Para este caso alcanzaría con fijar la fila de la referencia por lo tanto al anotar la fórmula para el primer registro se escribiría de esta forma: +B2*B$11.
Nota Importante: Para cambiar el tipo de referencia de una celda al escribirla se presiona F4.
Operadores de referencia
Los operadores de referencia son símbolos que se utilizan para indicar diferentes tipos de argumentos en una fórmula y existen tres tipos de operadores de referencia:
– Rango (dos puntos) produce una referencia para todas las celdas entre las dos referencias, incluyéndolas.
– Unión (punto y coma) produce una referencia que incluye las dos referencias.
– Mixta combinación de las dos anteriores.
Para hacer referencia a Escribir
Toda la columna A A:A
Toda la fila 1 1:1
Filas 1 al 3 1:3
Columnas A a la C A:C
El rango de A15 a A20 y C10 a C17 A15:A20;C10:C17
La hoja de calculo completa A:IV o 1:16384
Introducir referencias
Es posible introducir las referencias en las fórmulas al escribirlas. Sin embargo, la manera más fácil es seleccionar la celda o el rango directamente en la hoja de cálculo. Después de escribir un signo igual o un operador, simplemente haga clic en la celda o arrastre por el rango de celdas en el que desea introducir la referencia. La selección está rodeada por una línea punteada llamada borde móvil, y la referencia a la celda o el rango aparece en la fórmula.
Nota: – Para seleccionar celdas no adyacentes, hacer clic en la celdas manteniendo CTRL presionado.